개요
동시성 문제는 실무에서 자주 만난다. 이직 후 처음으로 진행하는 프로젝트에서 직접 채번을 해주는 로직을 구현해야 했는데, 테스트 중 동시성 문제가 발생해 비관적 락을 통해 동시성 제어를 해야 했다. 이 밖에도 재고 관리나 주문 시스템에서 여러 사용자가 동시에 같은 데이터를 건드릴 때 동시성 문제가 많이 발생한다. 이번에 Spring Data JPA를 통해 직접 코드로 구현해보면서 동시성 문제와 제어 방법을 이해해보자
아래 링크에서 코드를 확인할 수 있다.
practice-java-spring/spring-concurrency at master · chanbinme/practice-java-spring
Contribute to chanbinme/practice-java-spring development by creating an account on GitHub.
github.com
개발 환경
- Java 21
- Spring Boot 3.x
- Gradle
- Spring Data JPA
- Spring Retry
- JUnit
- IntelliJ
낙관적 락(Optimistic Lock) vs 비관적 락(Pessimistic Lock)
우선 낙관적 락, 비관적 락이 무엇인지 간단하게 살펴보고 시작하자
낙관적 락
낙관적 락은 대부분의 트랜잭션이 충돌하지 않을 것이라고 낙관적으로 가정하고, 데이터 수정 시점에서만 충돌을 감지하는 방식이다. DB의 락 기능을 사용하지 않고, 엔티티에 Version 애너테이션을 추가하여 애플리케이션 레벨에서 동시성 문제를 제어한다.
DB 락을 사용하지 않기 때문에 성능 저하가 적고, 충돌이 드물 때 적합하다. 하지만 충돌 발생시점에서 예외가 발생하므로, 충돌이 자주 발생하는 환경에서는 재시도 로직이 많아져 오히려 비효율적일 수 있다.
동작 방식
- 엔티티를 조회할 때 버전 정보를 함께 읽어온다.
- 데이터를 수정할 때, 현재 버전과 DB에 저장된 버전이 일치하는지 확인한다.
- 만약 다른 트랜잭션이 먼저 데이터를 수정해서 버전이 바뀌었다면, 예외가 발생하고 트랜잭션이 롤백된다.
- 충돌이 발생하면 애플리케이션에서 후처리(재시도, 알림 등)를 해줘야 한다.
적용 방법
엔티티에 @Version 애너테이션을 추가하거나 Repository에서 @Lock(LockModeType.OPTIMISTIC) 애너테이션을 사용하여 적용할 수 있다.
@Entity
public class Item {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Comment("아이템 이름")
private String name;
@Comment("아이템 재고 수량")
private int stockQuantity;
@Version
private Long version;
}
비관적 락
비관적 락은 트랜잭션 충돌이 자주 발생할 것으로 비관적으로 가정하고, 데이터를 읽거나 수정할 때 DB에 락을 건다.
데이터 정합성을 확실하게 보장하기 때문에 충돌이 자주 발생하는 환경에서 적합하다. 하지만 락이 걸린 동안 다른 트랜잭션은 대기해야 하기 때문에 성능 저하, 데드락 등의 위험이 있어 주의하여 사용해야 한다.
동작 방식
- 데이터를 읽거나 수정하는 순간, 해당 데이터에 락을 건다.
- 락이 걸린 데이터는 트랜잭션이 끝날 때까지 다른 트랜잭션에서 읽거나 수정할 수 없다.
- 락을 얻지 못한 트랜잭션은 대기하거나, 타임아웃이 발생할 수 있다.
적용 방법
Repository 메서드에 @Lock(LockModeType.PESSIMISTIC_WRITE) 또는 @Lock(LockModeType.PESSIMISTIC_READ) 애너테이션을 사용한다. 그러면 JPA가 해당 쿼리를 락 쿼리(FOR UPDATE)로 변환한다.
public interface ItemRepository extends JpaRepository<Item, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<Item> findById(Long id);
}| 구분 | 낙관적 락 | 비관적 락 |
| 락 방식 | 버전 관리, 애플리케이션 단 | DB 락, 트랜잭션 단 |
| 충돌 처리 | 충돌 시 예외 발생, 롤백 | 락 대기, 트랜잭션 순차 처리 |
| 성능 | 충돌 적을 때 유리 | 충돌 많을 때 유리 |
| 단점 | 충돌 많으면 재시도 부담 | 성능 저하, 데드락 위험 |
| 적용 방법 | @Version, OPTIMISTIC 락 | PESSIMISTIC 락 어노테이션 |
코드
아래는 상품 수량을 감소시키는 일반적인 코드이다. 코드는 아주 단순한 로직이기 때문에 딱 봤을 때는 큰 문제가 없어보인다.
하지만 이 로직은 동시성 문제를 일으킬 수 있는 코드이다. 글로만 보면 쉽게 이해가 되지 않기 때문에 직접 테스트를 통해 동시성 문제 발생 상황을 살펴보고 직접 동싱성 제어를 해보자
@Entity
@Getter
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class Item {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Comment("아이템 이름")
private String name;
@Comment("아이템 재고 수량")
private int stockQuantity;
public void decreaseStock(int quantity) {
int restStock = this.stockQuantity - quantity;
if (restStock < 0) {
throw new RuntimeException("재고가 부족합니다. 현재 재고: " + this.stockQuantity + ", 요청 수량: " + quantity);
}
this.stockQuantity = restStock;
}
}@Service
@RequiredArgsConstructor
public class ItemService {
private final ItemRepository itemRepository;
@Transactional
public int decreaseStock(Long itemId, int quantity) {
Item item = itemRepository.findById(itemId)
.orElseThrow(() -> new RuntimeException("상품을 찾을 수 없습니다."));
item.decreaseStock(quantity);
return item.getStockQuantity();
}
@Transactional(readOnly = true)
public Item getItem(Long itemId) {
return itemRepository.findById(itemId)
.orElseThrow(() -> new RuntimeException("상품을 찾을 수 없습니다."));
}
}public interface ItemRepository extends JpaRepository<Item, Long> {
Optional<Item> findById(Long id);
}동시성 테스트
이제 동시성 제어를 하지않았을 때, 낙관적 락, 비관적 락을 적용했을 때에 따라 결과를 테스트해보자.
아래 테스트는 여러 사용자(스레드)가 동시에 같은 상품의 재고를 차감할 때, 서비스가 데이터 일관성을 보장하는지(예: 재고가 음수로 내려가거나 중복 차감되지 않는지) 확인하기 위해 작성된 동시성 테스트 코드이다. 실제 운영 환경에서 발생할 수 있는 동시 요청 상황을 만들어서 비관적 락 등 동시성 제어가 제대로 동작하는지 검증한다. 코드의 세부 내용은 주석을 참고 바란다.
테스트 흐름
- 초기 데이터 세팅: 재고가 100개인 아이템을 저장한다.
- 동시 요청 시뮬레이션: 10개의 스레드를 동시에 실행하여, 각각 아이템의 재고를 1씩 차감하는 요청을 보낸다.
- 동시성 제어 검증: 각 스레드가 차감에 성공하면, 남은 재고 수량을 기록한다. 예외가 발생하면 실패 카운트를 기록한다. 모든 스레득 작업을 마칠 때까지 대기한다.
- 결과 검증: 재고 차감 기록(수량 히스토리)에 중복이 없는지 확인한다. 최종 재고가 90(=100-10)이 되었는지 확인한다. 성공/실패 스레드 수, 재고 변화 히스토리 등을 출력해 동시성 문제 여부를 파악한다.
@SpringBootTest
public class ItemConcurrencyTest {
@Autowired
private ItemService itemService;
@Autowired
private ItemRepository itemRepository;
@BeforeEach
void setUp() {
// 테스트를 위한 초기 데이터 설정
Item item = Item.builder()
.name("Red Potion")
.stockQuantity(100)
.build();
itemRepository.save(item);
}
@Test
public void concurrencyTest() throws InterruptedException {
// given
int threadCount = 10; // 동시 실행할 스레드 수
ExecutorService executor = Executors.newFixedThreadPool(threadCount); // 스레드 풀 생성
Set<Integer> quantityHistory = ConcurrentHashMap.newKeySet(); // 재고 수량 기록을 위한 Set(중복 방지)
int originalStockQuantity = itemService.getItem(1L).getStockQuantity(); // 초기 재고 수량
CountDownLatch latch = new CountDownLatch(threadCount); // 모든 스레드가 작업을 완료할 때까지 대기하는 CountDownLatch
// when
// 10개의 스레드를 생성하여 동시에 재고 감소 작업을 수행
AtomicInteger successCount = new AtomicInteger(0); // 성공한 스레드 수를 기록하기 위한 AtomicInteger
AtomicInteger failureCount = new AtomicInteger(0); // 실패한 스레드 수를 기록하기 위한 AtomicInteger
for (int i = 0; i < threadCount; i++) {
executor.submit(() -> {
try {
int stockQuantity = itemService.decreaseStock(1L, 1); // 아이템 ID 1의 재고를 1 감소(비관적 락 적용)
quantityHistory.add(stockQuantity); // 현재 재고 수량을 기록
successCount.incrementAndGet(); // 성공한 스레드 수 증가
} catch (Exception e) {
failureCount.incrementAndGet(); // 실패한 스레드 수 증가
System.err.println("재고 감소 실패: " + e.getMessage()); // 예외 메시지 출력
} finally {
latch.countDown(); // 작업 완료 시 CountDownLatch 감소
}
});
}
latch.await();
executor.shutdown();
// then
Item item = itemService.getItem(1L);
System.out.println("성공한 스레드 수: " + successCount.get());
System.out.println("실패한 스레드 수: " + failureCount.get());
System.out.println("재고 수량 기록: " + quantityHistory.stream().sorted().toList());
System.out.println("최종 수량: " + item.getStockQuantity());
assertAll(
() -> assertEquals(threadCount, quantityHistory.size()), // 중복 없이 재고 수량 기록
() -> assertEquals(originalStockQuantity - threadCount, item.getStockQuantity()) // 최종 재고 수량이 90이어야 함
);
}
}💡 ExecutorService와 CountDownLatch란?
ExecutorService는 자바에서 멀티스레드 작업을 효율적으로 관리하기 위한 인터페이스로, 스레드 생성, 실행, 종료 등 복잡한 작업을 직접 제어하지 않고도 작업(쓰레드)을 실행할 수 있도록 도와준다. 스레드 풀(Thread Pool)을 사용해 미리 여러 개의 스레드를 만들어두고, 작업이 들어올 때마다 스레드 풀에서 스레드를 할당해 실행한다.
CountDownLatch는 여러 스레드가 작업을 모두 마칠 때까지 다른 스레드(또는 메인 스레드)가 기다릴 수 있도록 도와주는 동기화 도구이다. 생성 시 지정한 숫자(count)만큼 countDown()이 호출될 때까지 await()로 대기하고, 숫자가 0이 되면 대기 중인 스레드가 모두 진행된다. 주로 "여러 작업이 모두 끝날 때까지 기다렸다가 다음 단계로 진행"하는 상황에 사용한다. 멀티스레드 환경에서 작업 동기화 및 완료 시점 제어가 쉽기 때문에 테스트 코드, 병렬 처리, 비동기 작업 등 다양한 곳에 활용된다.
동시성 제어를 하지 않았을 때
별도 동시성 제어를 하지 않고 테스트를 진행해보자. 어떤 결과가 나올까?

성공한 스레드 수: 10
실패한 스레드 수: 0
재고 수량 기록: [99]
최종 수량: 99시원하게 테스트를 실패했다. 남겨 놓은 로그를 보면 10명이 동시에 1개씩 상품의 재고를 감소시켰음에도 불구하고, 최종 상품 수량이 90이 아닌 99로 나온다. 즉, 분명히 10번의 차감이 일어났어야 하지만 실제로는 단 1개만 차감된 셈이다.
더 큰 문제는 모든 스레드가 작업을 성공적으로 마무리했다고 로그에 남았다는 것이다. 표면적으로는 아무런 오류나 예외가 발생하지 않았지만, 실제로는 데이터가 꼬이고, 기대한 결과와 완전히 다른 값이 나온다. 이처럼 동시성 제어 없이 여러 스레드가 동시에 같은 데이터를 수정할 때, 데이터 무결성이 쉽게 깨질 수 있고, 문제를 인지하지 못한 채 잘못된 결과가 저장될 수 있다. 이런 점이 바로 동시성 문제의 무서움이자, 멀티스레드 환경에서 적절한 동시성 제어(락, 트랜잭션 등)가 반드시 필요한 이유라고 생각한다.
비관적 락
이제 비관적 락을 통해 동시성 제어를 해보자. JPA에서는 Repository 메서드에 @Lock(LockModeType.PESSIMISTIC_WRITE)을 붙여서 쉽게 비관적 락을 적용할 수 있다. 이제 해당 스레드의 작업이 끝날 때까지 다른 스레드는 해당 데이터에 읽기/쓰기 작업을 할 수 없다.
테스트를 진행해보자
public interface ItemRepository extends JpaRepository<Item, Long> {
/**
* 아이템을 ID로 조회한다. 쓰기 락을 사용하여 동시성 문제를 방지한다.
* 쓰기 락을 사용하면 해당 아이템을 조회하는 동안 다른 트랜잭션이 해당 아이템을 수정할 수 없다.
*/
@Lock(LockModeType.PESSIMISTIC_WRITE)
@QueryHints({ @QueryHint(name = "javax.persistence.lock.timeout", value = "10000") })
Optional<Item> findById(Long id);
}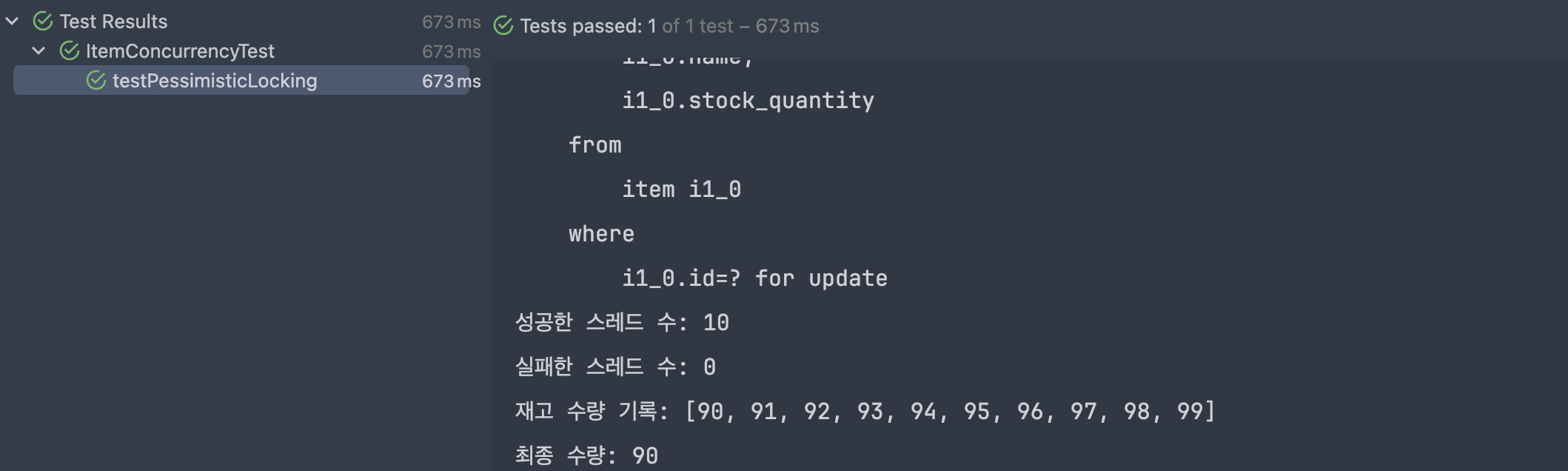
성공한 스레드 수: 10
실패한 스레드 수: 0
재고 수량 기록: [90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
최종 수량: 90테스트가 시원하게 통과했다. 로그를 살펴보면 재고가 순차적으로 차감되는 모습을 명확하게 확인할 수 있다.
이미지 속 쿼리에서도 볼 수 있듯이, @Lock(LockModeType.PESSIMISTIC_WRITE) 어노테이션을 사용하면 해당 쿼리에 FOR UPDATE가 자동으로 붙어 데이터베이스 레벨에서 락이 걸린다.
만약 MyBatis나 직접 쿼리를 작성하는 경우에는, 쿼리문에 직접 FOR UPDATE를 추가하여 동일하게 동시성 제어를 적용할 수 있다.
이렇게 적절한 락 설정을 통해 여러 스레드가 동시에 접근해도 데이터의 일관성과 무결성을 안전하게 보장할 수 있다.
select
i1_0.id,
i1_0.name,
i1_0.stock_quantity
from
item i1_0
where
i1_0.id=? for update -- Lock💡 비관적 락에는 읽기 락과 쓰기 락이 있는데 쓰기 락을 적용한 이유는?
비관적 락에는 읽기(PESSIMISTIC_READ)와 쓰기(PESSIMISTIC_WRITE) 두 가지 유형이 있다. 여기서 쓰기 락을 적용한 이유는 쓰기 락이 걸린 데이터에 대해서는 다른 트랜잭션이 해당 데이터를 읽거나 쓸 수 없도록 완전히 배타적인 락을 거는 반면, 읽기 락은 다른 트랜잭션이 읽기는 허용하지만 쓰기는 허용하지 않기 때문이다.
만약 읽기 락만 적용한다면, 여러 스레드가 동시에 데이터를 읽고, 그 값을 기반으로 각각 별도의 쓰기 작업을 시도할 수 있다. 이 경우 동시성 제어가 제대로 이루어지지 않아, 동일한 데이터를 여러 번 읽고 동시에 갱신하는 상황이 발생할 수 있고, 결과적으로 동시성 제어를 하지 않았을 때와 동일하게 데이터 불일치 문제가 발생할 수 있다. 반면, 쓰기 락(PESSIMISTIC_WRITE)을 사용하면 한 번에 하나의 트랜잭션만 해당 데이터에 대해 읽기와 쓰기 모두를 수행할 수 있으므로, 여러 스레드가 동시에 재고를 차감하는 상황에서도 데이터의 일관성과 무결성을 보장할 수 있다. 따라서, 정확한 동시성 제어와 데이터 무결성을 위해서 쓰기 락을 적용했다.
락 타임아웃
비관적 락을 적용한 코드에서 주목할 부분은 @QueryHint이다. 비관적 락은 데이터베이스에서 실제로 데이터에 락을 걸어 동시성 문제를 방지하지만, 여러 트랜잭션이 동시에 같은 데이터에 접근할 경우, 한 트랜잭션이 락을 보유하고 있으면 다른 트랜잭션은 락이 해제될 때까지 대기하게 된다. 이때 별도의 타임아웃을 지정하지 않으면, 락을 획득하려는 트랜잭션이 무한정 대기할 수 있어 서비스 지연이나 장애로 이어질 수 있다. 이를 방지하기 위해 @QueryHint를 통해 락 타임아웃을 걸 수 있는데, MySQL, PostgresSQL 등 @QueryHint가 동작하지 않는 DB들이 있기 때문에 해당 DB에 맞춰 설정을 해줘야 한다. 이 부분은 추후에 관련 글을 작성할 생각이다.
낙관적 락
낙관적 락은 엔티티에 @Version 애너테이션을 붙인 version 필드를 추가하면 사용할 수 있다. 이 version 컬럼을 통해 update 시점에 DB의 데이터와 조회했던 데이터가 일치한 상태인지 체크할 수 있다. 만약 일치하지 않는다면 예외를 발생시킨다. 테스트를 해보자
@Entity
@Getter
@Builder
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@AllArgsConstructor
public class Item {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Comment("아이템 이름")
private String name;
@Comment("아이템 재고 수량")
private int stockQuantity;
@Version
private Long version;
public void decreaseStock(int quantity) {
if (this.stockQuantity < quantity) {
throw new RuntimeException("재고가 부족합니다. 현재 재고: " + this.stockQuantity + ", 요청 수량: " + quantity);
}
this.stockQuantity -= quantity;
}
}
예상대로 실패한다. 실제 쿼리를 살펴보면, 업데이트 조건에 ID뿐만 아니라 버전(version) 필드도 포함되어 있어 JPA가 버전 기반의 낙관적 락을 적용한 것을 확인할 수 있다. 이로 인해 동시성 제어를 하지 않았을 때와는 달리, 성공한 스레드와 실패한 스레드가 명확히 구분된다.
update item
set
name=?,
stock_quantity=?,
version=?
where
id=?
and version=?실패한 스레드는 ObjectOptimisticLockingFailureException 예외를 발생시킨다. 예외 메시지를 보면 "다른 트랜잭션에서 데이터를 수정하거나 삭제했다"라고 되어 있기 때문에 데이터 충돌이 발생했음을 알 수 있다. 요구사항에 따라 이 예외를 catch해서 재시도 로직을 구현하거나, 사용자에게 알림을 보내는 등 후처리를 할 수 있다.
재고 감소 실패: class org.springframework.orm.ObjectOptimisticLockingFailureException
- Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect): [com.chanbinme.springconcurrency.numbersequence.Item#1]
재시도 처리
@Retryable 애너테이션을 사용하면 특정 메서드 실패 시 재시도 처리를 할 수 있다.
ObjectOptimisticLockingFailureException가 발생했을 때 재시도 처리를 할 수 있도록 해보자
Application.class
@EnableRetry // 추가
@SpringBootApplication
public class SpringConcurrencyApplication {
public static void main(String[] args) {
SpringApplication.run(SpringConcurrencyApplication.class, args);
}
}
build.gradle
dependencies {
...
// spring retry
implementation 'org.springframework.retry:spring-retry'
}@Service
@RequiredArgsConstructor
public class ItemService {
private final ItemRepository itemRepository;
@Transactional
@Retryable(
value = {OptimisticLockException.class},
maxAttempts = 10, // 최대 10번 재시도
backoff = @Backoff(delay = 200) // 재시도 간 200ms 대기
)
public int decreaseStock(Long itemId, int quantity) {
Item item = itemRepository.findById(itemId)
.orElseThrow(() -> new RuntimeException("Item not found"));
item.decreaseStock(quantity);
return item.getStockQuantity();
}
...
}
참조
https://www.baeldung.com/java-jpa-transaction-locks
https://www.baeldung.com/spring-retry
https://www.baeldung.com/spring-data-jpa-query-hints
https://docs.spring.io/spring-data/jpa/reference/jpa/query-methods.html
JPA Query Methods :: Spring Data JPA
By default, Spring Data JPA uses position-based parameter binding, as described in all the preceding examples. This makes query methods a little error-prone when refactoring regarding the parameter position. To solve this issue, you can use @Param annotati
docs.spring.io
https://www.ibm.com/docs/en/was/8.5.5?topic=tja-troubleshooting-jpa-deadlocks-transaction-timeouts
Troubleshooting JPA deadlocks and transaction timeouts
Database deadlocks and transaction timeouts are the result of contention between two or more clients attempting to access the same database resource. Deadlock is a special case where a circular blocking condition between two or more clients, each blocked b
www.ibm.com
'JPA' 카테고리의 다른 글
| JPA - JPA에서 일괄 삭제하는 방법과 주의점 (deleteAllById, deleteAllByIdIn, deleteAllByIdInBatch, Querydsl) (3) | 2024.12.04 |
|---|---|
| JPA - 연관 관계를 위한 불필요한 select 줄이기(getReferenceById()) (0) | 2024.11.18 |
| Querydsl - Expressions클래스로 select에서 상수 사용하는 법 (1) | 2024.11.14 |
| Spring Data JPA - 외래키(Foreign Key)를 복합 기본키(Composite Primary Key)로 사용하기 (1) | 2024.11.08 |
| JPA - 하나의 컬럼에 여러 개의 데이터를 저장하기 (0) | 2023.05.08 |